One of the advantages of BI EE is its ability to make cross database
joins. Currently, BI Server component of BI EE supports database joins
across any database. This feature is primarily meant for joins between a
database and some lookup tables coming from Excel files. Though this
would work for databases too, its not recommended to use them in a
production environment since BI EE does the joins in memory by
extracting the data from the source databases first. We will see how to
go about creating a simple cross database join today. There is not much
difference in the way we actually set up the repository. But still i
thought this deserves its own blog entry since its a very unique feature
of BI EE. We shall simulate this using 2 simple tables. One table (EMP
table of the normal Oracle SCOTT schema) would be from Oracle and the
other table would be from an Excel file. For demonstration purposes we
shall be exporting the normal DEPT table from the SCOTT schema in the
form of an excel file. So, basically we have 2 tables.
EMP Table in an Oracle Database
DEPT Table in an EXCEL file
Our final aim is to create a simple report in Answers with data
coming in from both the EMP table and the DEPT table. In order to do
that the first step is to import the EMP Table from the Oracle Database
into the repository.
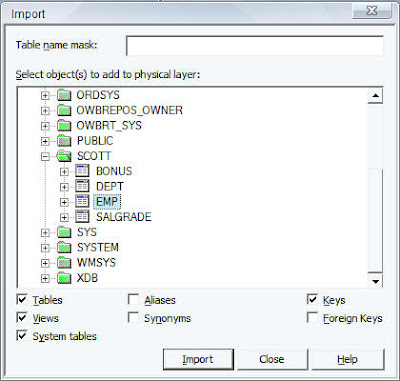
Similarly, import the Excel file (which is basically an export of the DEPT table) using ODBC.
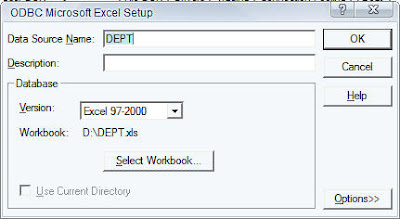
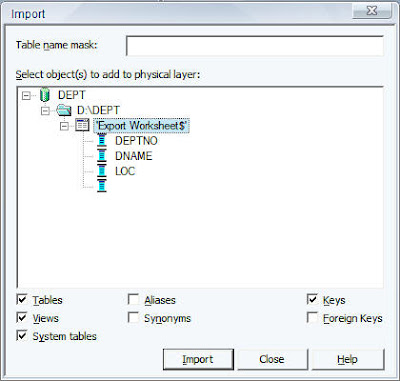
So, our repository should basically have 2 tables in 2 different databases as shown below.
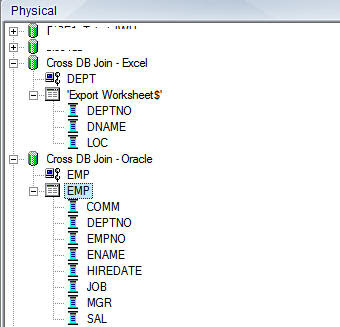
Once this is done, the next step is to create a join between these 2
tables in the physical layer.Typically, if you go to the physical layer
diagram, it would allow joins only between tables in the same database.
In order to achieve cross-database joins, the first step is to right
click on the EMP table and then click on Physical Diagram -> All
Objects and Joins.
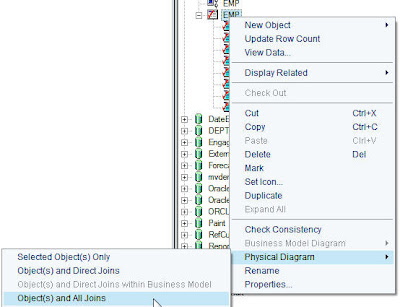
In the same way (ensure that the physical Diagram window is open), right click and click on view physical diagram on the DEPT Excel table source. That will automatically bring both the tables inside the physical layer.
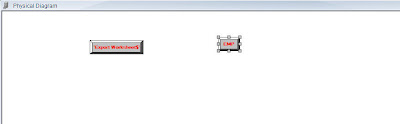
Now, create a database join between both the tables using DEPTNO as the join column.
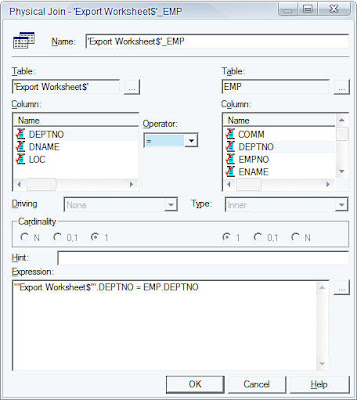
Once this is done, save the changes made in the repository. Now,
create a new Business Model Cross DB join. Drag and drop both the tables
(DEPT and EMP) from the physical layer into the Cross DB join Business
Model. Then right click on Cross DB Join and click on view the Business
Model diagram.
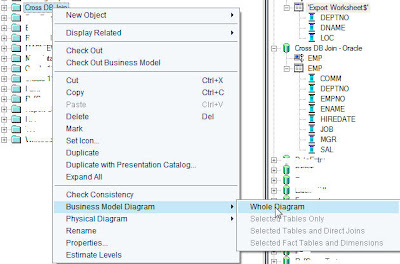
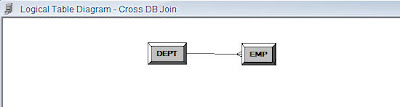
Similar to what we did in the Physical layer, create a foreign key join between DEPT and the EMP table based on DEPTNO column.
Once this is done, drag and drop the Business Model into the
Presentation layer and save the repository. Ensure that your repository
is clear of any warnings or errors. Once this is done, go to Answers and
try creating a simple report having DNAME and SAL as thecolumns.
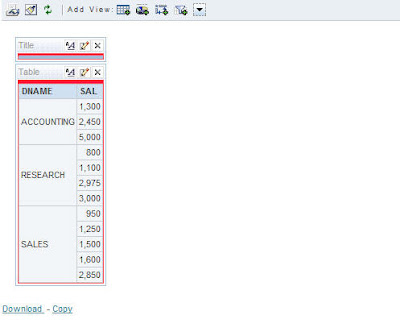
As you see, we have now created a report that contains data from 2
different data sources. The BI Server does the joins in the background.
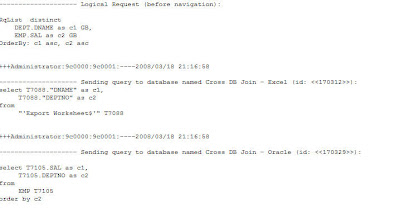
To see what exactly the BI Server, is doing, lets look at the logs to
get the exact SQL. You would basically see 2 SQLs. They are
select T7105.SAL as c1,and
T7105.DEPTNO as c2
from
EMP T7105
order by c2
select T7088.”DNAME” as c1,
T7088.”DEPTNO” as c2
from
“‘Export Worksheet$'” T7088